.avif)

.avif)
.avif)
.avif)
.avif)
.avif)
Blinkin VLM beginnt mit Standardtrainingsaufgaben. Bei der Modellierung maskierter Sprachen werden Teile eines Satzes ausgeblendet und das Modell sagt die fehlenden Wörter voraus. Bei der Modellierung maskierter Bilder werden Teile eines Bildes ausgeblendet und das Modell rekonstruiert sie. Diese Aufgaben helfen dem Modell, starke Text- und Bilddarstellungen getrennt voneinander zu erstellen. Ein Schüler-Encoder arbeitet mit den maskierten Eingaben, während ein Lehrer-Encoder die vollständigen Daten sieht.
Connecting the Dots — Visual Token Decoding trainiert Blinkin VLM, Bilder am Text auszurichten. Beispielsweise prognostiziert das Modell anhand eines Diagramms und seiner Beschreibung anhand von Text- und Bilddaten die fehlenden Beschriftungen („visuelle Zeichen“). Dadurch entsteht eine starke Verbindung zwischen dem, was es liest, und dem, was es sieht, und ermöglicht so modalübergreifendes Denken.
Dieses Ziel trainiert Blinkin VLM darin, den Inhalt einer maskierten Region in einem Bild anhand von Umgebungsbildern und Text vorherzusagen. Es kann beispielsweise eine Phrase wie „der Fuchs“ mit dem richtigen Teil eines Bildes verknüpfen. Dies hilft dem Modell, detaillierte Diagramme zu handhaben, in denen es auf bestimmte Komponenten ankommt, wie z. B. wissenschaftliche Illustrationen.
Dadurch wird Blinkin VLM trainiert, Text mit bestimmten Teilen eines Bildes zu verbinden. Bei einem maskierten Bereich verwendet das Modell Umgebungsbilder und eine Beschreibung, um vorherzusagen, was fehlt. Steht im Text beispielsweise „der Fuchs“, lernt es, die richtige Stelle im Bild zu lokalisieren. Diese feinkörnige Abbildung eignet sich besonders für Diagramme und detaillierte Grafiken.
Bild-Text-Matching: Sicherstellung der Kohärenz. In diesem Schritt erkennt das Modell Bild-Text-Paare und entscheidet, ob sie übereinstimmen. Dadurch werden Grafiken und Beschreibungen auf globaler Ebene aufeinander abgestimmt. Dabei werden nicht nur Objekte oder Wörter erkannt, sondern auch festgestellt, ob das Bild als Ganzes zum Text passt.
Stellen Sie eine Verbindung zu Tools wie HubSpot, Notion, Airtable, Salesforce oder Ihrem Projektstapel her.
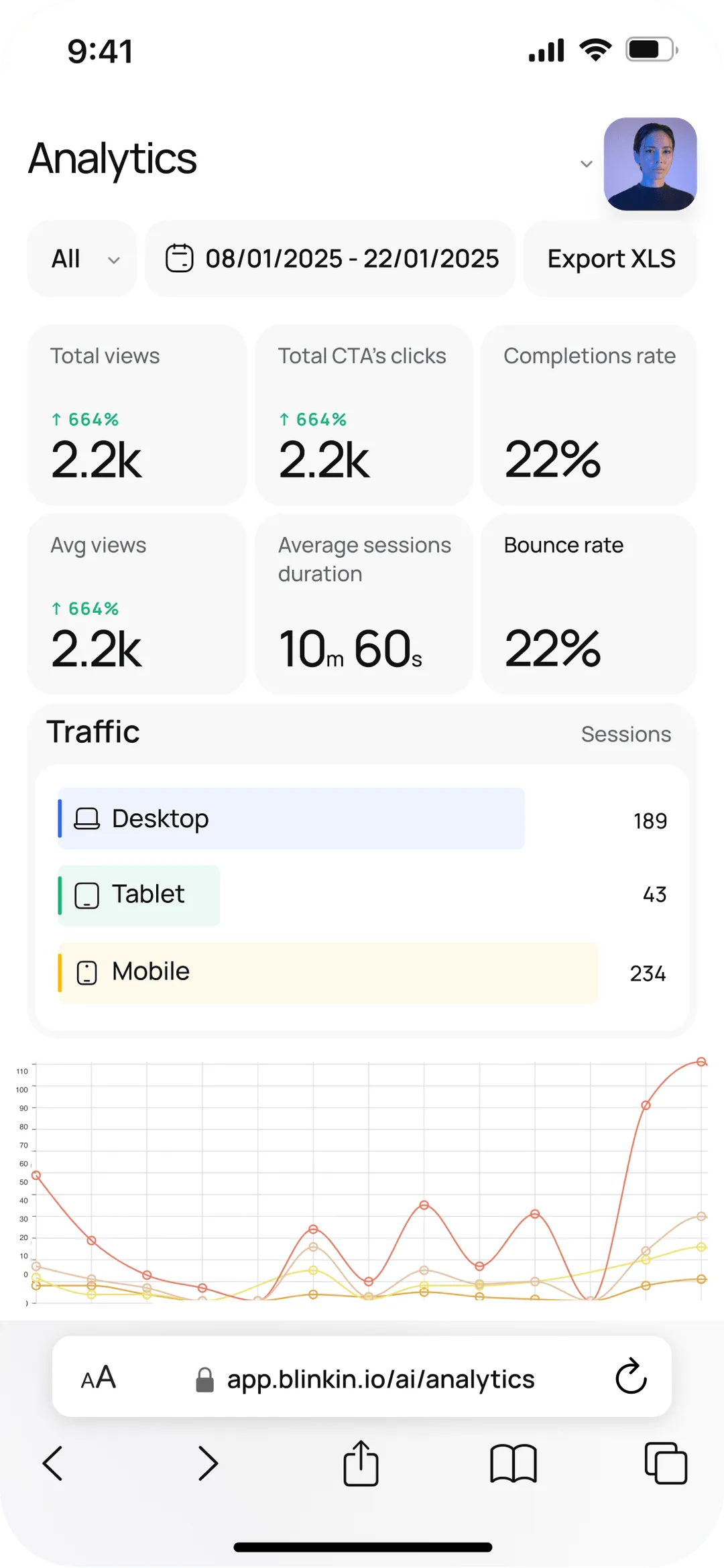
Verfolgen Sie Aufrufe, Abschlüsse, Drop-Offs und Einblicke in das Engagement in all Ihren Formularen, Videos und KI-Chats — in Echtzeit.
.avif)