.avif)

.avif)
.avif)
.avif)
.avif)
.avif)
Blinkin VLM begins with standard training tasks. In masked language modeling, parts of a sentence are hidden and the model predicts the missing words. In masked image modeling, parts of an image are hidden and the model reconstructs them. These tasks help the model build strong text and image representations separately. A student encoder works with the masked inputs, while a teacher encoder sees the full data.
Connecting the Dots - Visual Token Decoding trains Blinkin VLM to align visuals with text. For example, given a diagram and its description, the model predicts the missing labels (“visual tokens”) using both text and image data. This builds a strong connection between what it reads and what it sees, enabling cross-modal reasoning.
This objective trains Blinkin VLM to predict the contents of a masked region in an image using both surrounding visuals and text. For example, it can link a phrase like “the fox” to the correct part of an image. This helps the model handle detailed diagrams where specific components matter, such as scientific illustrations.
This trains Blinkin VLM to connect text with specific parts of an image. Given a masked region, the model uses surrounding visuals and a description to predict what’s missing. For example, if the text says “the fox,” it learns to pinpoint the right spot in the image. This fine-grained mapping is especially useful for diagrams and detailed visuals.
Image-Text Matching: Ensuring Coherence. In this step, the model sees image–text pairs and decides if they match. This pushes it to align visuals and descriptions at a global level — not just recognizing objects or words, but understanding whether the image as a whole fits the text.
Connect to tools like HubSpot, Notion, Airtable, Salesforce, or your project stack.
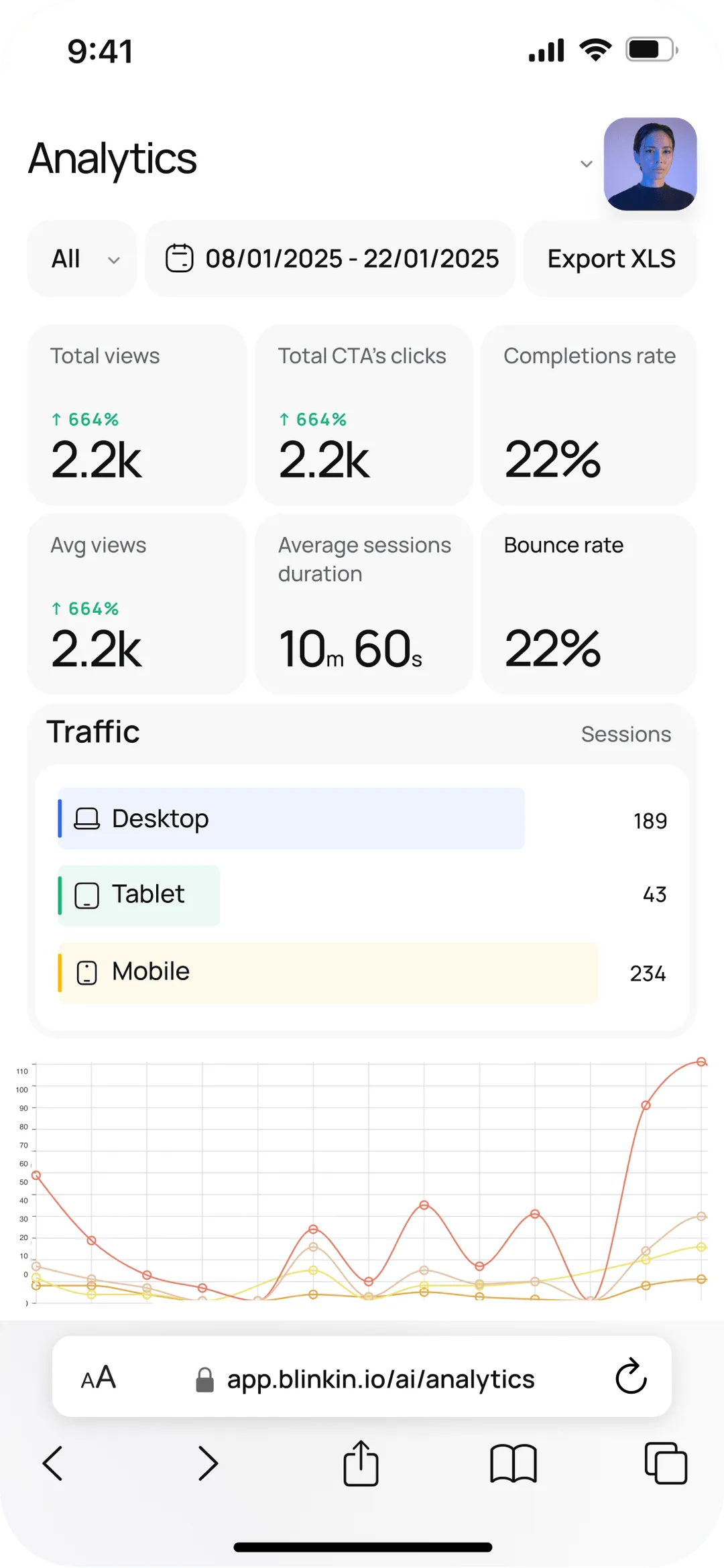
Track views, completions, drop-offs, and engagement insights across all your forms, videos, and AI chats - in real time.
.avif)